К Claude у меня подключены Figma, таск-трекер, база знаний и аналитика канала. Я не написал ни строчки кода для интеграции — просто поставил четыре сервера, и ассистент сам разобрался, что умеет каждый.
Сижу, смотрю на это и думаю: а почему оно вообще работает? Раньше так было нельзя.
Чтобы прикрутить чужой сервис к своей программе, ты открываешь доку API и руками пишешь клиент. Вот эндпоинт, вот поля, вот так авторизуйся. Под каждый сервис — заново. Сто программ, сто сервисов — и кто-то живой клеит десять тысяч интеграций.
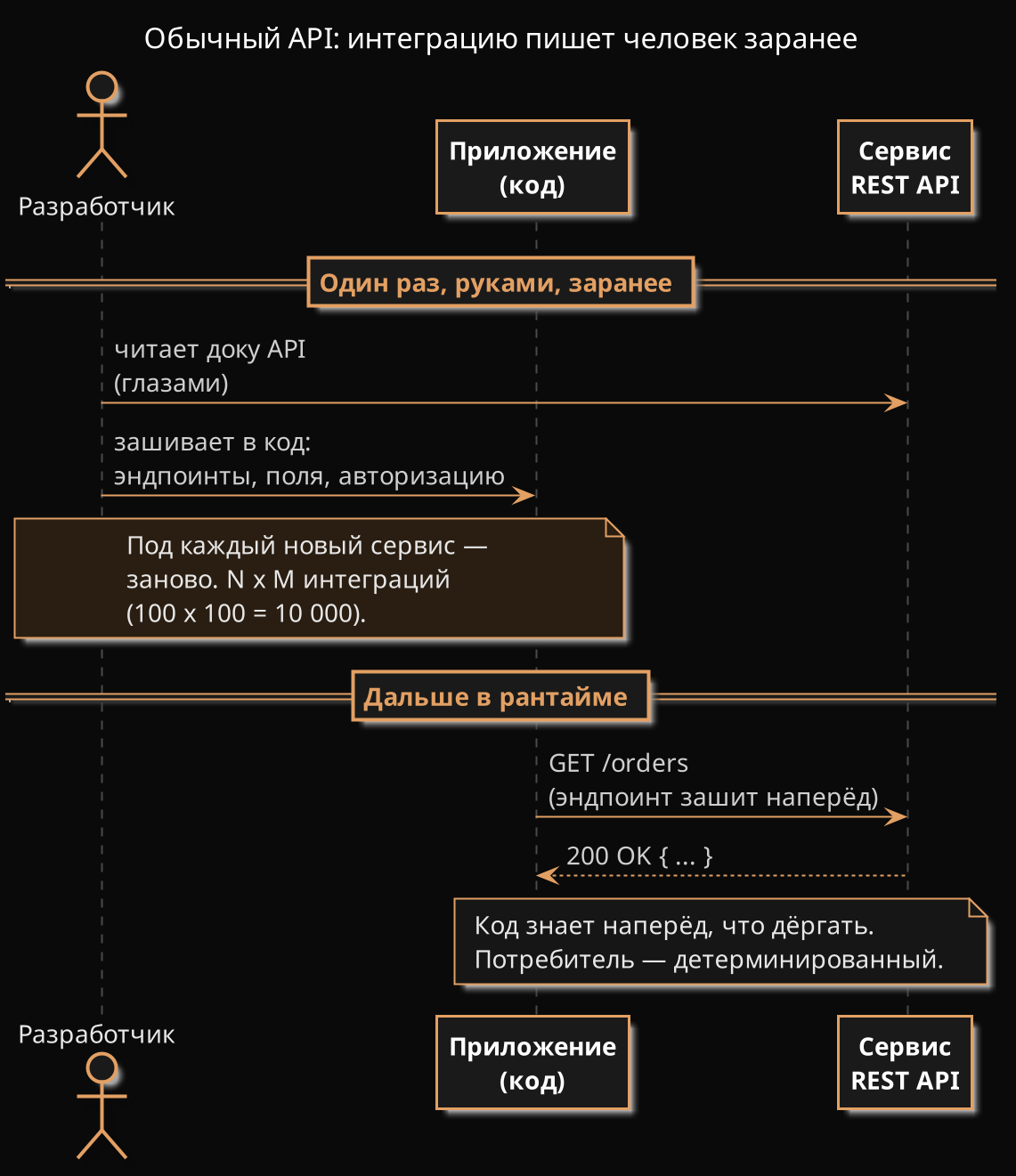
Вот это и ломает MCP (Model Context Protocol, придумали в Anthropic в конце 2024).
Что это по-простому
MCP — это общий разъём между ИИ-приложением и сервисами. Как USB-C: один протокол, втыкаешь что угодно.
Участников трое. Хост — само приложение (Claude, IDE, мой движок канала). Клиент сидит внутри хоста, держит связь один-на-один с сервером. Сервер — обёртка над сервисом, та самая Figma или трекер. Подробности на схеме ниже.
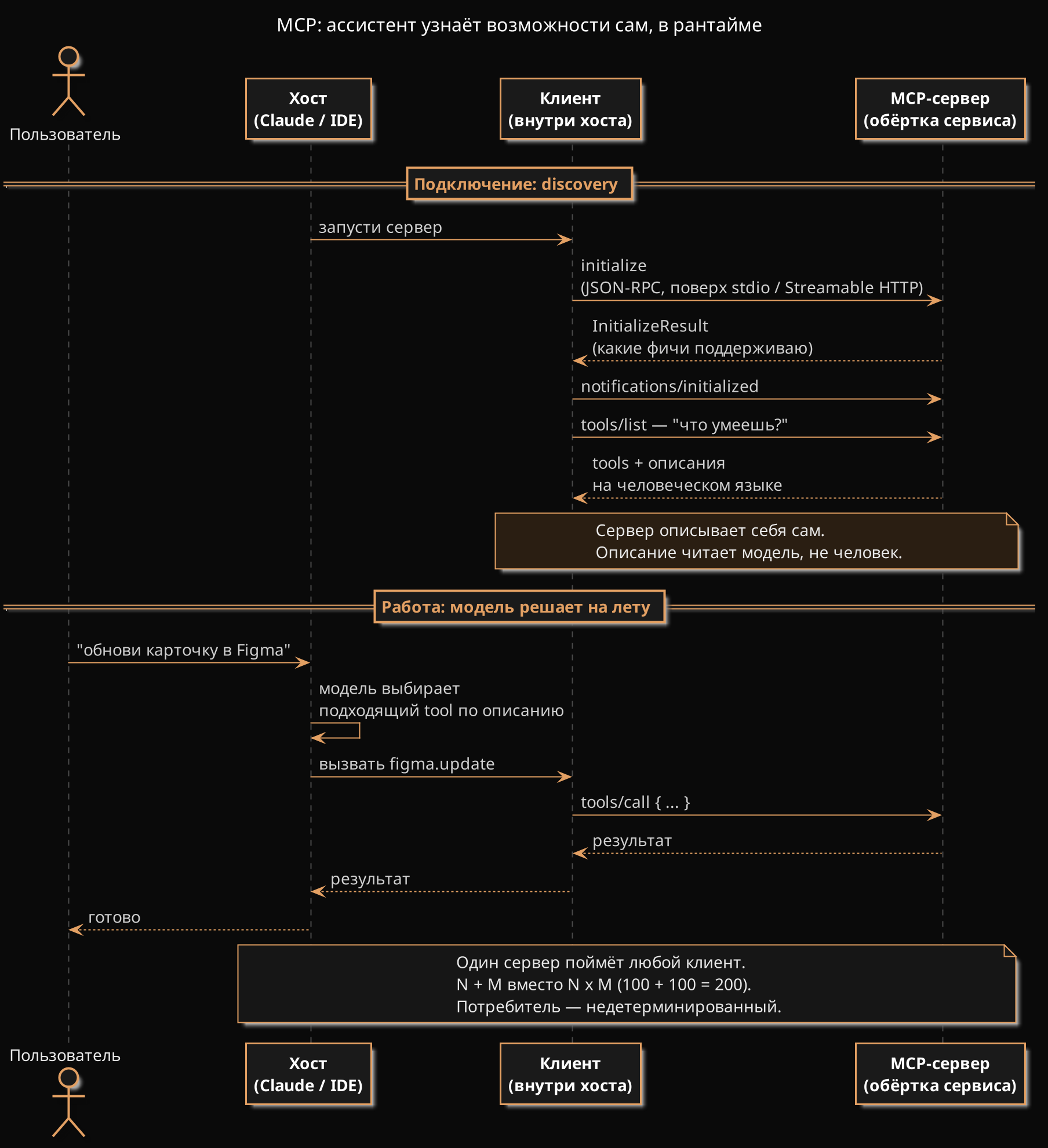
Что под капотом
Да почти ничего нового. Транспорт: stdio (сервер — отдельная программа рядом, общаются через ввод-вывод) или HTTP, если сервер удалённый. Сообщения — по JSON-RPC. По проводу тот же текст, что у REST-сервиса, только устроен иначе: не «дёрни ресурс по адресу», а «вызови вот этот метод» (RPC, удалённый вызов процедуры). Мелочь, но придирчивый разработчик поправит — говорю как есть.
Сервер отдаёт три типа штук — смотря кто командует вызовом: tools (действия, решает модель), resources (данные на чтение, даёт приложение — у меня та же аналитика канала), prompts (заготовки, зовёт человек). Дальше по делу — только tools.
А теперь самое сочное
Когда клиент цепляется к серверу, он первым делом спрашивает: «ты что умеешь?» И сервер отвечает списком инструментов — с описаниями на человеческом языке. Не в доке для разработчика. Сам, в рантайме. И читает их не человек, а модель.
Вот тут весь фокус. Обычный API писали под код. Код дубовый и предсказуемый: ему один раз зашили доку — и он знает наперёд, какой эндпоинт дёрнуть и в каком порядке. А MCP пишут под модель. А она тупит и решает на ходу. Поэтому ей надо, чтобы сервер сам по-человечески рассказал, что умеет — иначе не сообразит, какой инструмент к месту.
На схемах выше это и есть «детерминированный» и «недетерминированный потребитель» — не пугайтесь слов: код знает заранее, модель прикидывает по ситуации.
А теперь посчитаем, в чём кайф. Сто программ, сто сервисов. Раньше — десять тысяч интеграций руками. С MCP — двести: написал сервер раз — поймёт любой клиент, написал клиент — подхватит любой сервер. (В фирме клиентов два-три, но суть та же: складываем, а не умножаем.) Руками под каждую пару клеить не надо.
Но не бесплатно
За то, что потребитель «думает сам», ты платишь. Описания всех инструментов висят в контексте модели: навешал тридцать тулов — половина окна забита, а ты ещё ничего не сделал. Плюс модель может выбрать не тот инструмент или дёрнуть лишнее — а если в данные с сервера подсунули вредный текст, она послушает его, а не тебя (привет, prompt injection). Поэтому на важных действиях — подтверждение, урезанные права, человек в цепочке. И ещё авторизация — отдельная морока: локально серверу всё равно, он под боком, а по HTTP будь добр нормальный OAuth — он же реальные системы дёргать будет.
Итого
MCP — никакой не новый API. Это старый API, которому переписали инструкцию: теперь её читает не кодер, а модель — сама смотрит, что умеет сервер, и сама решает, что дёрнуть.
Провод тот же. Поменялся только тот, кто его читает.
И вот что меня цепляет. Десять лет интеграционные аналитики писали ТЗ под каждый сервис руками — «дёрни GET /orders, поля такие-то». Вот эта часть обнуляется. Не вся: описания инструментов и guardrails (подтверждения, права) всё равно кто-то пишет — мы же. Но «клеить руками под каждую пару» уходит. Вопрос не «учить или нет», а «успеть, пока MCP не стал базой как SQL». Хотя, может, я и разогнался.